文字识别
from ascript.android.screen import Ocr
从屏幕中 识别文字,支持多引擎、便捷查找/点击/等待等操作。
- 识别屏幕上的按钮文字、标题、提示语,判断当前页面状态
- 自动点击"确认"、"登录"、"下一步"等文字按钮
- 等待"加载完成"、"操作成功"等提示出现后再执行下一步
- 提取屏幕上的数字(金额、倒计时、验证码等)
- 游戏中识别对话框、任务提示、背包物品名称
引擎选择
AScript 内置两个 OCR 引擎:
| 引擎 | 说明 | 速度 | 精度 |
|---|---|---|---|
Ocr.MODE_MLK | 谷歌 ML Kit V2 | ⚡ 快 | 高 |
Ocr.MODE_PADDLE_V2 | 百度 PP-OCR V5 | 中等 | 高,支持多语言 |
默认引擎为 MODE_PADDLE_V2(PP-OCR V5),可通过 set_engine 全局切换。
设置默认引擎
# 切换为谷歌 MLKit
Ocr.set_engine("mlkit")
# 切换为百度 PaddleOCR
Ocr.set_engine("paddle")
便捷方法
以下方法自动截屏、自动调用当前默认引擎,无需关心底层细节。
查找文字
在屏幕上查找文字,返回第一个匹配结果。
- 函数
Ocr.find(text, rect=None, mode=None, binary=-1, confidence=0.1, image=None)
- 参数
| 参数 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
| text | str | 是 | 要查找的文字(支持正则表达式) |
| rect | list | 否 | 搜索范围 [x, y, x1, y1] |
| mode | int | 否 | 引擎模式,None=使用默认引擎。Ocr.MODE_MLK=谷歌 MLKit,Ocr.MODE_PADDLE_V2=百度 PP-OCR V5 |
| binary | int | 否 | 二值化阈值,-1=不处理,0-255=二值化后再识别 |
| confidence | float | 否 | 可信度阈值,默认 0.1 |
| image | Bitmap/ndarray | 否 | 传入源图,None=自动截屏 |
- 返回值
匹配成功返回 dict,未找到返回 None
{
"text": "登录",
"rect": [320, 1080, 420, 1120],
"center_x": 370,
"center_y": 1100,
"confidence": 0.95
}
- 示例
from ascript.android.screen import Ocr
# 查找"登录"按钮
result = Ocr.find("登录")
if result:
print("找到:", result["text"], "位置:", result["center_x"], result["center_y"])
查找所有文字
返回所有匹配结果列表。text 传 None 可获取屏幕上全部文字。
- 函数
Ocr.find_all(text=None, rect=None, mode=None, binary=-1, confidence=0.1, image=None)
- 参数
同 Ocr.find(),其中 text 可为 None(返回所有识别结果)。
- 返回值
list[dict] 或 None
- 示例
from ascript.android.screen import Ocr
# 获取屏幕上所有文字
all_text = Ocr.find_all()
if all_text:
for item in all_text:
print(item["text"])
# 查找所有包含"设置"的结果
results = Ocr.find_all("设置")
判断文字是否存在
- 函数
Ocr.exists(text, rect=None, mode=None, binary=-1, confidence=0.1, image=None)
- 返回值
True 或 False
- 示例
from ascript.android.screen import Ocr
if Ocr.exists("登录"):
print("登录按钮存在")
找到文字并点击
找到文字后自动点击其中心位置。
- 函数
Ocr.click(text, rect=None, mode=None, binary=-1, confidence=0.1, timeout=0, image=None)
- 参数
| 参数 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
| text | str | 是 | 要查找并点击的文字 |
| timeout | float | 否 | 超时秒数,0=只尝试一次,>0=持续重试直到超时 |
| 其他参数 | - | - | 同 Ocr.find() |
- 返回值
True=点击成功,False=未找到
- 示例
from ascript.android.screen import Ocr
# 找到"确认"并点击
Ocr.click("确认")
# 最多等 5 秒,找到"下一步"就点击
Ocr.click("下一步", timeout=5)
等待文字出现
持续截屏识别,直到找到目标文字或超时。
- 函数
Ocr.wait(text, timeout=10, rect=None, mode=None, binary=-1, confidence=0.1, image=None)
- 返回值
匹配成功返回 dict(同 Ocr.find()),超时返回 None
- 示例
from ascript.android.screen import Ocr
# 等待"加载完成"出现,最多等 15 秒
result = Ocr.wait("加载完成", timeout=15)
if result:
print("页面已加载")
等待文字出现并点击
组合 wait + click,等到文字出现后自动点击。
- 函数
Ocr.wait_click(text, timeout=10, rect=None, mode=None, binary=-1, confidence=0.1, image=None)
- 返回值
True=点击成功,False=超时未找到
- 示例
from ascript.android.screen import Ocr
# 等待"开始"按钮出现并点击,最多等 10 秒
Ocr.wait_click("开始", timeout=10)
底层引擎方法
如果需要更精细的控制,可以直接调用引擎方法。
谷歌 ML Kit V2
速度快,准确度高,支持中文+英文。
- 函数
Ocr.mlkitocr_v2(rect=None, pattern=None, confidence=0.5, bitmap=None, binary=-1, image=None)
- 参数
| 参数 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
| rect | list | 否 | 识别范围 [x, y, x1, y1] |
| pattern | str | 否 | 正则表达式,从识别结果中提取匹配文本 |
| confidence | float | 否 | 可信度阈值,默认 0.5 |
| bitmap | Bitmap | 否 | 传入图片,None=自动截屏 |
| binary | int | 否 | 二值化阈值,-1=不处理 |
| image | Bitmap/ndarray | 否 | 源图别名,支持 Bitmap 或 cv2 ndarray |
谷歌 OCR 没有可信度,识别到的文字即为结果。
- 返回值
OcrText 数组对象,每个元素包含:
OcrText {
text = '应用或小程序', # 识别到的文字
center_x = 345, # 文字中心 X 坐标
center_y = 202, # 文字中心 Y 坐标
rect = [320, 180, 644, 242] # 文字范围 [left, top, right, bottom]
}
- 示例
from ascript.android.screen import Ocr
# 识别屏幕全部文字
res = Ocr.mlkitocr_v2()
if res:
for r in res:
print("文字:", r.text, "位置:", r.center_x, r.center_y)
# 指定范围 + 正则过滤
res = Ocr.mlkitocr_v2(rect=[40, 122, 714, 659], pattern=".*程序.*")
百度 PP-OCR V5
基于 PP-OCR V5 引擎,高精度离线识别,支持多语言。
- 函数
Ocr.paddleocr(rect=None, pattern=None, confidence=0.1,
max_side_len=1200, precision=16,
bitmap=None, file=None, binary=-1,
language="chinese", image=None)
- 参数
| 参数 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
| rect | list | 否 | 识别范围 [x, y, x1, y1] |
| pattern | str | 否 | 正则表达式,提取匹配文本 |
| confidence | float | 否 | 可信度阈值,默认 0.1 |
| max_side_len | int | 否 | 图片最大边长,超过则等比缩放,默认 1200 |
| precision | int | 否 | 精度参数,默认 16 |
| bitmap | Bitmap | 否 | 传入图片,None=自动截屏 |
| file | str | 否 | 从文件中识别 |
| binary | int | 否 | 二值化阈值,-1=不处理 |
| language | str | 否 | 语言模型,默认 "chinese"(内置中英日韩),其他语言首次使用需下载 |
| image | Bitmap/ndarray | 否 | 源图别名,支持 Bitmap 或 cv2 ndarray |
- 返回值
OcrText 数组对象,同谷歌 OCR,额外包含 confidence 属性。
- 示例
from ascript.android.screen import Ocr
# 基本用法
res = Ocr.paddleocr()
if res:
for r in res:
print(r.text, r.confidence)
# 指定范围 + 正则 + 缩放
res = Ocr.paddleocr(rect=[40, 122, 714, 659], pattern=".*程序.*", max_side_len=1600)
# 指定语言
res = Ocr.paddleocr(language="en")
# 从文件识别
from ascript.android.system import R
res = Ocr.paddleocr(file=R.sd("test.png"))
Ocr.paddleocr_v2() 和 Ocr.paddleocr_v3() 为旧版兼容方法,内部均调用 Ocr.paddleocr(),已统一升级为 PP-OCR V5 引擎。
点阵字库识别
对特殊图像(如游戏数字、定制字体),使用点阵字库进行识别。
点阵字库适合小范围精确识别,不适合全屏检索。
- 函数
Ocr.matrix(font_lib, rect=None, region=0.9, image=None)
- 参数
| 参数 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
| font_lib | str | 是 | 字库文件路径 |
| rect | list | 否 | 识别范围 [x, y, x1, y1] |
| region | float | 否 | 识别精度 0-1,默认 0.9(90%) |
| image | Bitmap/ndarray | 否 | 传入源图,None=自动截屏 |
- 返回值
识别到的文字字符串,或 None
- 示例
from ascript.android.system import R
from ascript.android.screen import Ocr
# 识别指定范围内的点阵文字
text = Ocr.matrix(R.res("font.t"), rect=[90, 529, 343, 612])
print(text)
如何制作字库?
制作字库用到了图色工具中的点阵识字
- 打开图色助手并点击点阵字库
- 框选要做的字
- 按住键盘 1-9 取色要做的字,直到右侧出现字的二值图像
- 选择要存放字库的工程和文件名称(文件名默认
font.t,可以更改)。此文件存放在 "工程/res/" 目录下,会自动创建 - 填写文字代号
- 点击保存字体到字库
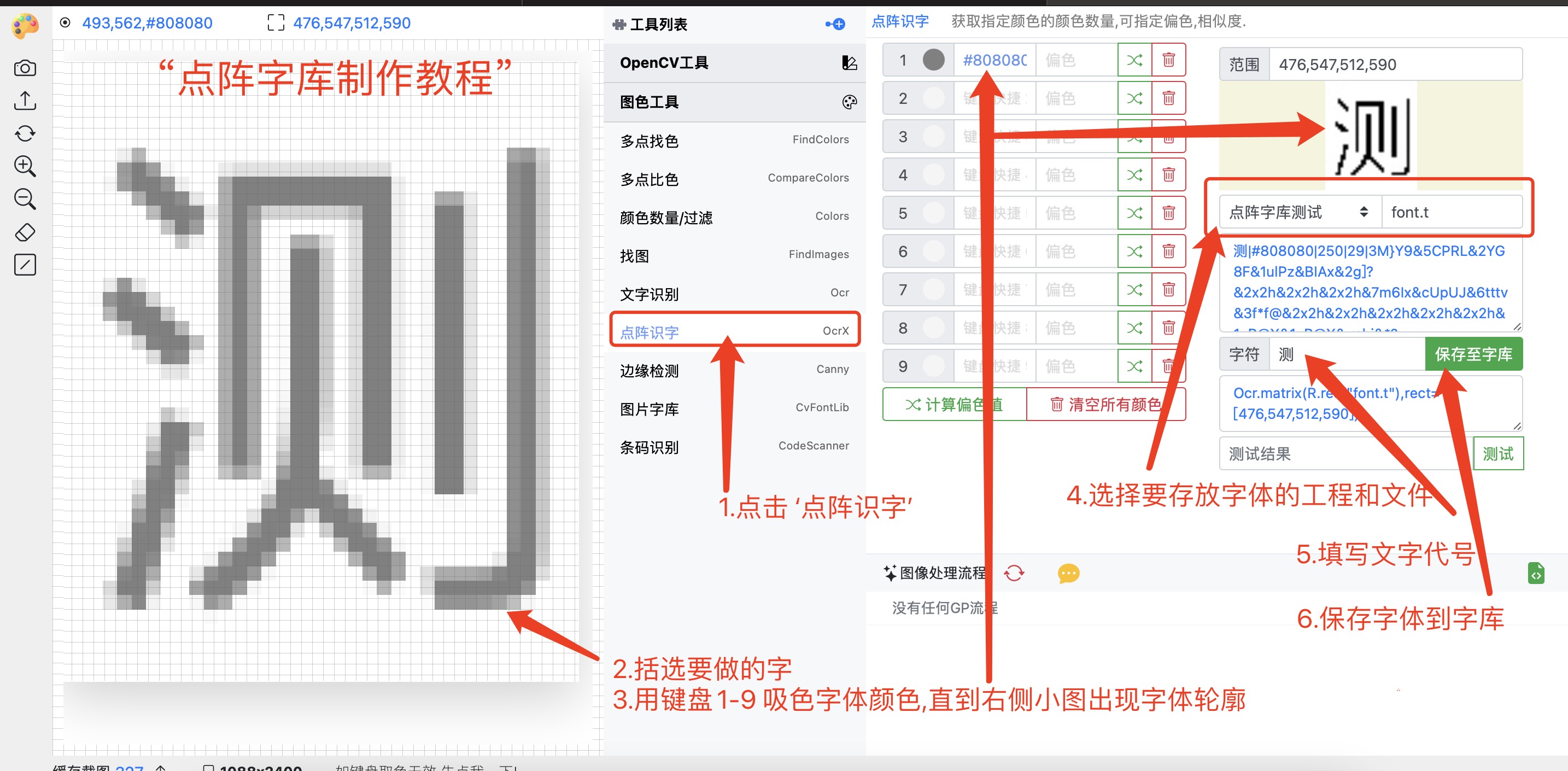
image 参数说明
所有方法都支持 image 参数,可传入 Android Bitmap 或 OpenCV ndarray,系统会自动转换类型:
from ascript.android.screen import Ocr, capture
# 自动截屏(默认行为)
Ocr.find("文字")
# 传入 Bitmap
bmp = capture()
Ocr.find("文字", image=bmp)
# 传入 OpenCV 图片
import cv2
img = cv2.imread("/sdcard/test.png")
Ocr.find("文字", image=img)